How to run a half-marathon in 10 lines of python
I got into running a number of years ago and one of the ways I've always found productive to get me out and make sure I get a bit of exercise is to enter races. That way I know I better make an effort to train or I'm going to look like an idiot on race day. A couple of months ago I was registered to run in the ABP Southampton Half Marathon. A couple of years ago there was a feature that allowed you to register your social media accounts and then they would tweet/post your progress out as you ran. This wasn't available in 2016 and didn't seem to be available this either so I decided to engineer my own solution.

What do we need to do?
The goal of the project is to enable almost real-time reporting of my performance in the race via my twitter account. To achieve this we are going to need to solve a number of discrete problems:
- I need to be able to programatically send a tweet from my twitter account.
- I need to know my current status in the race.
- I need to check if the race status has changed from the last time I got an update to decide whether there is something new to share.
- If there is a new result I need to craft an appropriate tweet.
How to send a tweet from python
In all honesty, this was what I expected to be the tricky part, turned out to be one of the easiest bits. Key to the ease of this solution was the Tweepy library.
import tweepy # Need to setup our twitter api credentials consumer_key = 'abcdefghijkl' consumer_secret = 'ABCDEFGHIJKL' access_token = '1234567890' access_token_secret = '1234567890-secret' # Now we connect to twitter using our credentials auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) my_api = tweepy.API(auth) # Finally we can then send our tweet my_api.update_status("I'm sending a tweet using Python! Hello world.")
How to keep track of a runners race status
Helpfully the ABP Southampton Half Marathon maintains a live website of each runners status thanks to DB MAX Sports Timing. The screen shot below shows my results after the race was over, however, in the weeks before the race the page already existed and I could see the empty results table. Hence, I was able to design a simple web scraper that would extract out my results.
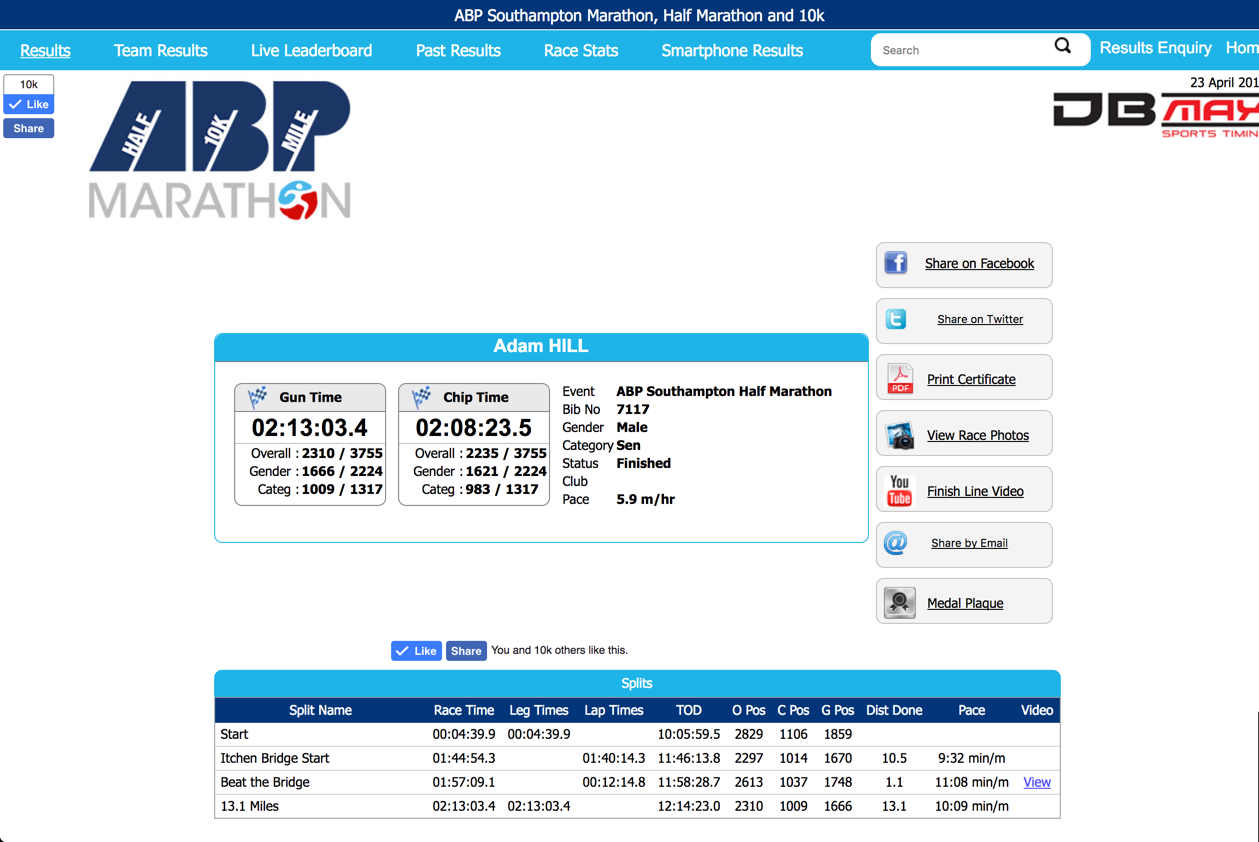
So we need to write a web scraper.
import requests from bs4 import BeautifulSoup import pandas as pd def get_timings(uri): """Get current web page data""" page = requests.get(uri) soup = BeautifulSoup(page.text, 'lxml') # Now find the table of timings start_row = soup.findAll('td', text='Start')[0] header = start_row.find_parent().find_previous_siblings()[0] columns = [] for tr in header.findAll('tr'): columns.append(tr.td.text) data = [] for row in header.find_next_siblings(): data_row = [] for td in row.findAll('td'): data_row.append(td.text) data.append(data_row) timings_df = pd.DataFrame(data, columns=columns) return timings_df
This little piece of python is a bit more complicated so it's worth taking the time to explain what's going on within the get_timings() function. The function takes a single argument that is the url of the webpage where the timings are located. We use the requests library to fetch the web content and then BeautifulSoup to search for all tables that have the text "Start" in them.
I always find webscraping to be more art than science. In this example I use the tools of BeautifulSoup to talk through the results table to get the features I need by first finding the header row and then looping over all of its siblings. I store the data as I go in a couple of lists and then convert it to a pandas DataFrame at the very end.
Keeping track of whether something has changed
Getting the instantaneous results from the webpage is all well and good, however, we don't want our tweetbot continually spamming the same tweet if nothing has changed. So to handle that we need to store what we saw when we last scraped the data. We could use a csv file but I decided to use a sqlite database in case I wanted to scale this up ever for multiple runners or track multiple races. If you aren't familiar with it sqlite is a simple, file based SQL database; you can read more here
Storing our scraped data in SQLITE
Fortunately for us pandas has already thought about people wanting to push results into a SQL database and has the DataFrame.to_sql() function. So having used out web-scraper to create a dataframe we just need to provide the database connection details to the function. Here we use the sqlite3 library.
We take bib number and a timings dataframe as inputs. We try and make a connection to our local database file and push the results out; in this instance we are always happy to overwrite any previous version of the database. If the connection isn't established we exit gracefully.
import sqlite3 as lite def push_timings_to_db(bib, timings_df): """Store the timings data in a sqlite database""" con = None try: con = lite.connect('abp_half_results.db') timings_df.to_sql('bib_{}'.format(bib), con, if_exists='replace') except lite.Error as e: print("Error %s:" % e.args[0]) sys.exit(1) finally: if con: con.close()
Comparing a new scrape to the old data
This is only half the battle, we also need to be able to fetch data back from the database in order to make comparisons to the current data. This function is almost the complete inverse of the previous piece of code. Now we connect to our sqlite database and use the pandas.read_sql() function to pull our data back out into a dataframe.
def fetch_timings_from_db(bib, timings_df): """Fetch the timings data from a sqlite database""" con = None try: con = lite.connect('abp_half_results.db') query_columns = ', '.join(['"'+col+'"' for col in timings_df.columns]) query = "SELECT {} FROM bib_{}".format(query_columns, bib) result = pd.read_sql(query, con) except lite.Error as error: print("Error %s:" % error.args[0]) sys.exit(1) finally: if con: con.close() return result
Now we need to test whether the stored results look any different to the current web results. This is achieved by doing a 'not equals' != check between the two python dataframe objects. If only one row has changed then a True boolean and the row is returned. If more than one row has changed then the last (i.e. most recent) row is the one returned.
def have_timings_changed(timings_df): """Testing if the timing data has changed""" result = fetch_timings_from_db() check = timings_df[(result != timings_df)["TOD"] == True] if check.shape[0] == 1: return True, check elif check.shape[0] > 1: nrows = check.shape[0] filt = [False if i<nrows-1 else True for i in range(nrows)] return True, check[filt] else: return False, check
Crafting a tweet for the race status
This component of the project is entirely open to what you would want to say. Personally, I chose to have a dedicated tweet for the start and another for the finish. Any intermediate results during the race would be a boiler plate reply that would then have the current time and pace.
def update_text(data_row, timings_df): """Function to generate text of a tweet update""" def _convert_to_dt(inp): """Try and convert to a datetime else return NaT""" try: return pd.to_datetime(inp) except ValueError: return pd.NaT timings = timings_df['TOD'].map(_convert_to_dt) max_time = (timings.max() - timings.min()) str_time = "{}h{}m{}s".format(max_time.components.hours, max_time.components.minutes, max_time.components.seconds) text = '' finished = False if data_row['Split Name'].iloc[0] == 'Start': text = "I crossed the start line of the Southampton Half Marathon at {} #ABPHalfand10K".format(data_row['TOD'].iloc[0]) elif data_row['Dist Done'].iloc[0] == "13.1": pace = max_time.seconds/60/13.1 str_pace = '{}:{} per mile'.format(int(pace), int((pace%1)*60)) text = "I've completed the Southampton Half Marathon in a time of {} with an average pace of {} #ABPHalfand10K".format(str_time, str_pace) finished = True else: curr_time = (pd.to_datetime(data_row['TOD'].iloc[0]) - timings.min()) str_curr_time = "{}h{}m{}s".format(curr_time.components.hours, curr_time.components.minutes, curr_time.components.seconds) text = "I've made it to {}; I've been running for {} and currently have a pace of {} #ABPHalfand10K".format(data_row['Split Name'].iloc[0], str_curr_time, data_row['Pace'].iloc[0]) return text, finished
Stitching it all together
If we now combine all of this together into a runner() class then we can make it generic for any runner and easy to "run" (excuse the pun). I'll also wrap my original tweeting code into a simple function.
import pandas as import pd import requests from bs4 import BeautifulSoup import sqlite3 as lite class runner(object): """Class to act as a runner""" def __init__(self, bib_number): """Constructor""" self.bib = bib_number self.uri = "http://dbmaxresults.co.uk/MyResults.aspx?CId=16421&RId=2166&EId=1&AId={}".format(int(self.bib)+192232) def get_timings(self): """Get current web page data""" page = requests.get(self.uri) soup = BeautifulSoup(page.text, 'lxml') # Now find the table of timings start_row = soup.findAll('td', text='Start')[0] header = start_row.find_parent().find_previous_siblings()[0] columns = [] for tr in header.findAll('tr'): columns.append(tr.td.text) data = [] for row in header.find_next_siblings(): data_row = [] for td in row.findAll('td'): data_row.append(td.text) data.append(data_row) self.timings_df = pd.DataFrame(data, columns=columns) def push_timings_to_db(self): """Store the timings data in a sqlite database""" con = None try: con = lite.connect('abp_half_results.db') self.timings_df.to_sql('bib_'+str(self.bib), con, if_exists='replace') except lite.Error as e: print("Error %s:" % e.args[0]) sys.exit(1) finally: if con: con.close() def fetch_timings_from_db(self): """Fetch the timings data from a sqlite database""" con = None try: con = lite.connect('abp_half_results.db') query_columns = ', '.join(['"'+col+'"' for col in self.timings_df.columns]) result = pd.read_sql("SELECT {} FROM bib_{}".format(query_columns, self.bib), con) except lite.Error as error: print("Error %s:" % error.args[0]) sys.exit(1) finally: if con: con.close() return result def have_timings_changed(self): """Testing if the timing data has changed""" result = self.fetch_timings_from_db() check = self.timings_df[(result != self.timings_df)["TOD"] == True] if check.shape[0] == 1: return True, check elif check.shape[0] > 1: nrows = check.shape[0] filt = [False if i<nrows-1 else True for i in range(nrows)] return True, check[filt] else: return False, check def update_text(self, data_row): """Function to generate text of a tweet update""" def _convert_to_dt(inp): """Try and convert to a datetime else return NaT""" try: return pd.to_datetime(inp) except ValueError: return pd.NaT timings = self.timings_df['TOD'].map(_convert_to_dt) max_time = (timings.max() - timings.min()) str_time = "{}h{}m{}s".format(max_time.components.hours, max_time.components.minutes, max_time.components.seconds) text = '' finished = False if data_row['Split Name'].iloc[0] == 'Start': text = "I crossed the start line of the Southampton Half Marathon at {} #ABPHalfand10K".format(data_row['TOD'].iloc[0]) elif data_row['Dist Done'].iloc[0] == "13.1": pace = max_time.seconds/60/13.1 str_pace = '{}:{} per mile'.format(int(pace), int((pace%1)*60)) text = "I've completed the Southampton Half Marathon in a time of {} with an average pace of {} #ABPHalfand10K".format(str_time, str_pace) finished = True else: curr_time = (pd.to_datetime(data_row['TOD'].iloc[0]) - timings.min()) str_curr_time = "{}h{}m{}s".format(curr_time.components.hours, curr_time.components.minutes, curr_time.components.seconds) text = "I've made it to {}; I've been running for {} and currently have a pace of {} #ABPHalfand10K".format(data_row['Split Name'].iloc[0], str_curr_time, data_row['Pace'].iloc[0]) return text, finished
def astroadamh_tweeter(tweet_txt): """Function to connect to the astroadamh twitter account""" consumer_key = 'abcdefghijkl' consumer_secret = 'ABCDEFGHIJKL' access_token = '1234567890' access_token_secret = '1234567890-secret' auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) my_api = tweepy.API(auth) my_api.update_status(tweet_txt)
Now we can run a half marathon in 10 lines of Python
We can tell that there aren't going to be an awful lot of updates based upon the timings webpage, so we:
- Initiate an instance of the runner class with the appropriate bib number.
- Create a twitterbot ready to send out our tweets.
- Use a while loop to monitor if we've finished the race.
- For the duration of the race we check to see if there is a status change and if so we tweet about it. Then we wait 5 minutes to check again.
myRunner = runner(7117); myTweetBot = astroadamh_twitter() finished = False while not finished: myRunner.get_timings() status, data = myRunner.have_timings_changed() if status: tweet, finished = myRunner.update_text(data) myTweetBot.tweet(tweet) myRunner.push_timings_to_db() time.sleep(5*60)
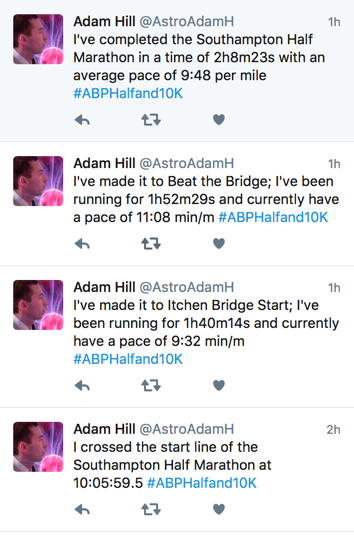
And at the end of that we see the following
Comments
Comments powered by Disqus